







已知两点经纬度计算球面距离的公式,一搜一大堆,形式如下:
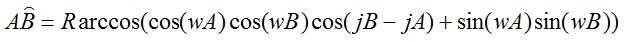
可是至于这个公式为什么是这样的,今天推导了一下,详细推导过程如下。首先画个图(图1),要不然空间想象能力差的话容易犯糊涂。首先对图1做个大致的说明,红色的半圆表示赤道,蓝色的圆弧表示本初子午线(也就是经度为0的子午线)。球最上方是北极点,点A和点B分别为要计算的两个点,坐标分别为A(jA,wA)和B(jB,wB)。
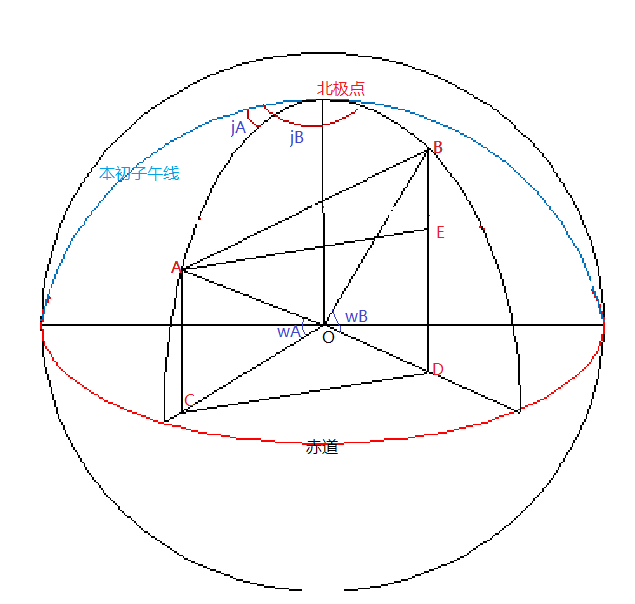
图1 示意图
再开始推导之前,我们需要在图中绘制一些辅助线,便于后面的描述和推导。如图1所示,A(jA,wA),B(jB,wB)两点分别为球面上的两点,坐标为经纬度表示。延A、B两点分别做垂直于赤道平面的垂线交赤道面为C、D两点。连接C、D两点,然后过A做CD的平行线交BD与点E。至此,所有的辅助线绘制完毕。假设地球为一个规则的圆球,半径为R(其实地球是一个椭球体,赤道的半径比极地的半径稍微大一点点)。
第一步:确定已知条件,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1945
1945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









