







前言
机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归、逻辑回归、Softmax回归、神经网络和SVM等等,主要学习资料来自Standford Andrew Ng老师在Coursera的教程,同时也参考了大量网上的相关资料(在后面列出)。
本文主要记录我在学习神经网络过程中的心得笔记,共分为三个部分:
Neural network - Representation:神经网络的模型描述;
Neural network - Learning:神经网络的模型训练;
Neural network - Code:神经网络的代码实现。
引言
在本文中,我们将神经网络看作是一个分类算法,其输出是样本属于某类别的概率值 P(y==k|x;Θ),暂时不去考虑深度学习中用于特征学习的复杂卷积神经网络。因此,本文将按照一个分类模型的维度去安排文章结构,包括模型结构及数学描述、模型训练等,记录我在学习神经网络过程中的心得和思考。
注意,
在不同的教程、论文以及其他资料中,对同一个算法或模型的描述多少会有一些差异,但本质的原理都是一致的,例如在神经网络的相关资料中,有些资料描述模型时是将偏置单元与隐藏单元一起计算,有些资料却是将偏置单元单独计算,但无论怎么描述,偏置单元的作用都是一致的。
本文是我在学习神经网络模型描述(Representation)时的笔记,主要以Andrew Ng老师在Coursera课程中以及UFLDL Tutorial中的关于神经网络模型的资料为主,文章小节安排如下:
1)神经网络的背景
2)神经网络模型
3)激活函数(activation function)
4)假设函数(hypothesis function)
5)模型对比:Logistic regression VS Neural Network
神经网络的背景
神经网络算法的来源可以从字面意思看出来,也就是模拟大脑的工作机制,实现学习、认知、决策等复杂功能。关于神经网络的背景介绍可以参看下面一段描述(摘自Coursera Andrew Ng的课程资料(ML wiki page)):
Neural networks are limited imitations of how our own brains work. They’ve had a big recent resurgence because of advances in computer hardware.
There is evidence that the brain uses only one “learning algorithm” for all its different functions. Scientists have tried cutting (in an animal brain) the connection between the ears and the auditory cortex and rewiring the optical nerve with the auditory cortex to find that the auditory cortex literally learns to see.
This principle is called “neuroplasticity” and has many examples and experimental evidence.
———————————————————————
也就是说,实验证明大脑利用同一个学习算法实现了听觉、视觉等等所有的功能,这也是神经网络算法美好的愿景。关于神经网络的起源和发展历史等具体背景资料这里不做介绍,感兴趣的朋友可以参考网上的资料和一些综述性论文。
神经网络模型
1)神经元(neuron)
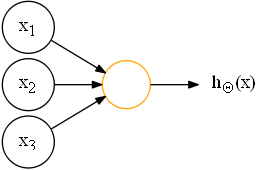
神经元,或称神经单元/神经节点,是神经网络基本的计算单元,其计算函数称为激活函数(activation function),用于在神经网络中引入非线性因素,可选择的激活函数有:Sigmoid函数、双曲正切函数(tanh)、ReLu函数(Rectified Linear Units)等。
2)神经网络(neural network)
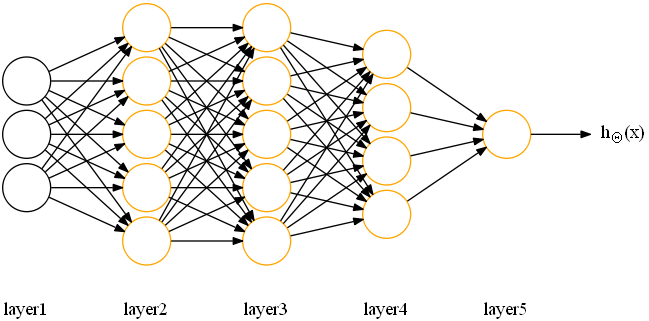
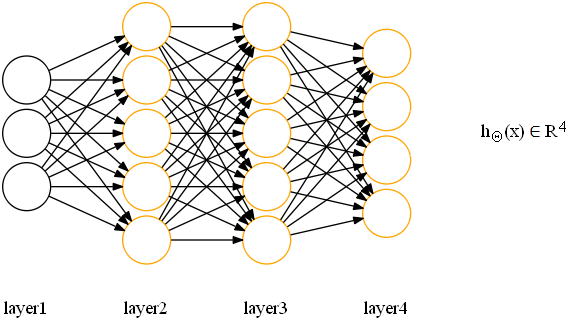
第一个网络结构对应一个二分类问题;
第二个网络结构对应一个多分类问题(K=4);
可以看出,神经网络其实就是许多神经元的组合,基于这样一个模型结构,神经网络可以完成复杂的非线性分类任务。
注意,
3)神经网络中的层(layer)和节点(node)
>>Layer
在上面的神经网络中,
最左边的层称为输入层(input layer),对应样本特征;
最右边的层称为输出层(output layer),对应预测结果;
>>Node
输入层节点:对应样本的特征输入,每一个节点表示样本的特征向量 x 中的一个特征变量或称特征项;
输出层节点:对应样本的预测输出,每一个节点表示样本在不同类别下的预测概率;
隐藏层节点:对应中间的激活计算,称为隐藏单元(hidden unit),在神经网络中隐藏单元的作用可以理解为对输入层的特征进行变换并将其层层传递到输出层进行类别预测;
备注,
神经网络中的隐层和隐藏单元是比较难理解的概念,同时也是神经网络的关键,一开始未必能够准确的理解,但一定要在学习和使用过程中反复理解。
4)神经网络符号描述
神经网络中多出了权重矩阵(参数矩阵)、激活值的概念,其实对这些概念的理解最好是参看英文原文,如下(摘自ML wiki page):
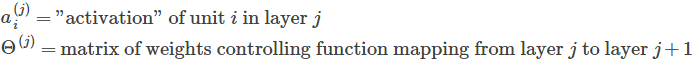
5)偏置单元
偏置单元(bias unit),在有些资料里也称为偏置项(bias term)或者截距项(intercept term),它其实就是函数的截距,与线性方程 y=wx+b 中的 b 的意义是一致的。在 y=wx+b中,b表示函数在y轴上的截距,控制着函数偏离原点的距离,其实在神经网络中的偏置单元也是类似的作用。
因此,神经网络的参数也可以表示为:(W, b),其中W表示参数矩阵,b表示偏置项或截距项。
神经网络结构中对偏置单元的计算处理方式有两种,
第一,设置偏置单元=1,并在参数矩阵 Θ 中设置第 0 列对应偏置单元的参数,对应的神经网络如下:
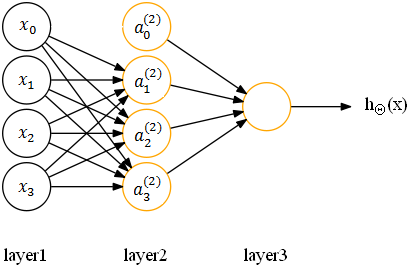
其中,x0 是第一层的偏置单元(设置为1),Θ(1)10 是对应该偏置单元 x0 的参数;a(2)0 是第二层的偏置单元,Θ(2)10 是对应的参数。
在计算激活值时按照(以a(2)1为例):
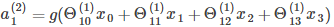
第二,设置偏置单元,不在参数矩阵中设置对应偏置单元的参数,对应的神经网络如下:
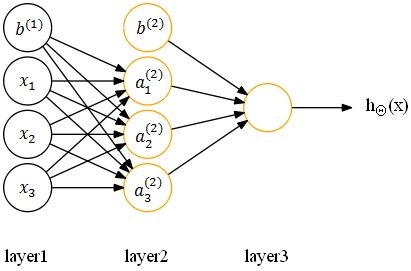
其中,b(1) 是 W(1) 对应的偏置单元向量,b(2) 是 W(2) 对应的偏置单元向量,b(1)1 是对应 a(2)1 的偏置单元。注意,此时神经网络的参数表示更改为:(W, b)
在计算激活值时按照:
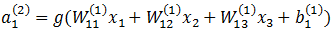
综上,
两者的原理是一致的,只是具体的实现方式不同。
其实在大部分资料和论文中看到的神经网络的参数都是表示为:(W, b),其中W代表weight,b代表bias。包括在UFLDL Tutorial中也是采用 (W, b) 表示,只是在Coursera上Andrew Ng老师的在线教程中看到将神经网络参数表示为 Θ,个人还是更喜欢 (W, b) 这种表示,很清晰。
激活函数(activation function)
神经单元的计算过程称为激活(activation),是指一个神经元读入特征,执行计算,并产生输出的过程。
激活函数是非线性函数,用于为神经网络模型加入非线性因素,使其能够处理复杂的非线性分类任务,一般来说神经网络选择Sigmoid函数,其他也可以选择双曲正切函数(tanh)、ReLu函数(Rectified Linear Units)等。
计算公式如下:
Sigmoid函数(0~1):
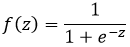
Tanh函数(-1~1):
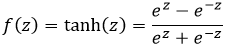
ReLu函数(0~+∞):
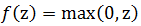
激活函数对比如下:
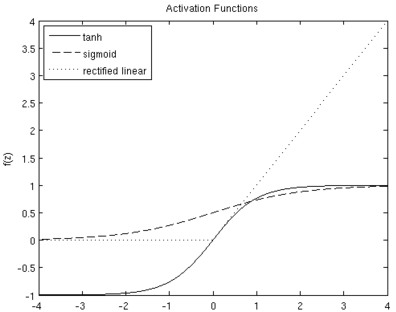
激活函数是在不断发展的,在神经网络的发展过程中,科学家们逐步发现了许多具有不同的性质的激活函数,可以更好地促进神经网络在实际问题中的应用。
例如,2001年,神经科学家Dayan、Abott从生物学角度,模拟出了脑神经元接受信号更精确的激活模型,提出了近似生物神经激活函数(Softplus function),对比如下:
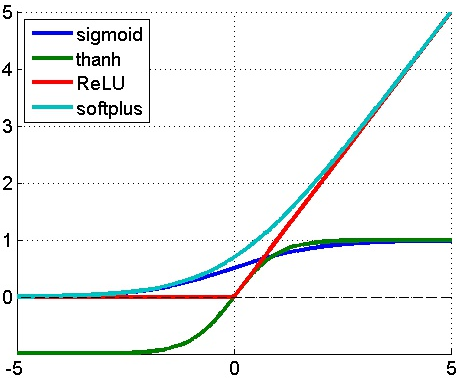
目前,ReLU函数在神经网络模型研究和实际应用中应用的更多,因为使用sigmoid或tanh作为激活函数做无监督学习时,会遇到梯度消失问题(gradient vanishing problem)导致无法收敛,而ReLU可以避免这个问题;另一方面,基于ReLU这种线性激活函数的神经网络的计算开销也是相对较低的。
备注,
其实,激活函数的作用可以看作是从原始特征学习出新特征,或者说是将原始特征从低维空间映射到高维空间。一开始也许无法很好的理解激活函数的意义和作用,但一定要记住,引入激活函数是神经网络具有优异性能的关键所在,多层级联的结构加上激活函数,令多层神经网络可以逼近任意函数,从而可以学习出非常复杂的假设函数。
关于激活函数的理解以及不同激活函数的对比可以参考如下文章:
参考1:知乎:神经网络激励函数的作用是什么?有没有形象的解释?
参考2:知乎:请问人工神经网络中的activation function的作用具体是什么?为什么ReLu要好过于tanh和sigmoid function?
参考3:ReLu(Rectified Linear Units)激活函数
假设函数(hypothesis function)
如果神经网络采用sigmoid函数作为激活函数,那么其假设函数就与逻辑回归模型一致,也是一个Sigmoid函数,可以看作是一个条件概率:P(y=1|x; Θ) 。
对于神经网络,其预测值的计算是一个逐层递进的过程,以下面的神经网络为例,
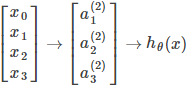
其预测值的计算过程如下:
>>计算隐藏单元的激活值
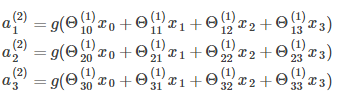
>>计算hθ(x)
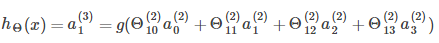
可以看到,
无论网络结构中有多少个隐层,最后在计算假设函数时,其实是与逻辑回归一致的。只是逻辑回归直接对样本特征计算,而神经网络中是对隐藏单元的激活值计算。
从该计算过程可以看出来,神经网络在对样本进行预测时,是从第一层(输入层)开始,层层向前计算激活值(称为激活-activation),直观上看这是一种层层向前传播特征或者说层层向前激活的过程,最终计算出 hΘ(x) ,这个过程称之为前向传播(forward propagation)。
备注,
神经网络计算输出的过程称为前向传播,无论多复杂的神经网络,在前向传播过程中其实也就是在不断的计算激活函数,从输入层一直计算到输出层,最后得到样本的预测标签。
模型对比:Logistic regression VS Neural Network
(1)基础模型对比
只具有一层(一个输入层)的神经网络模型,其实就是标准的逻辑回归模型,对比如下:
>>逻辑回归
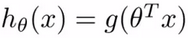
>>神经网络
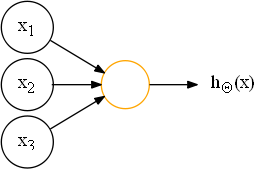
可以说,神经网络就是由一个个逻辑回归模型连接而成的,它们彼此作为输入和输出。
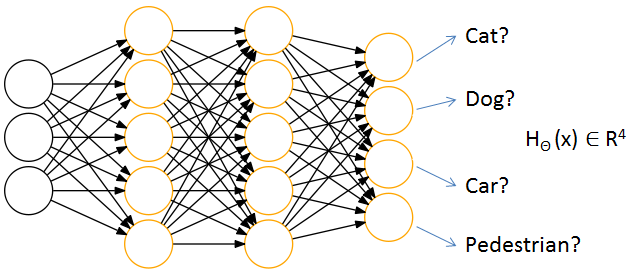
(2)多分类模型对比
在逻辑回归中,决策边界由 θ’x=0 决定,随着参数项的增加,逻辑回归可以在原始特征空间学习出一个非常复杂的非线性决策边界(也就是一个复杂非线性方程);
在神经网络中,决策边界由 ΘX=0 决定(这只是一个象征性表达式,Θ表示所有权重矩阵,X表示特征加上所有隐藏单元),其实神经网络算法并没有直接在原始特征空间学习决策边界,而是将分类问题映射到了一个新的特征空间,通过解决新特征空间的分类问题(学习决策边界),从而对应解决原始特征空间的分类问题。
(3)决策边界对比
在逻辑回归中,决策边界由 θ’x=0 决定,随着参数项的增加,逻辑回归可以在原始特征空间学习出一个非常复杂的非线性决策边界(也就是一个复杂非线性方程);
在神经网络中,决策边界由 ΘX=0 决定(这只是一个象征性表达式,Θ表示所有权重矩阵,X表示特征加上所有隐藏单元),其实神经网络算法并没有直接在原始特征空间学习决策边界,而是将分类问题映射到了一个新的特征空间,通过解决新特征空间的分类问题(学习决策边界),从而对应解决原始特征空间的分类问题。
(4)性能对比
在决策边界对比部分可以看出,逻辑回归和神经网络都可以学习复杂非线性决策边界,那么这里就存在这样一个问题:
同样是解决复杂非线性分类问题,神经网络相对于逻辑回归的优势在哪里?
参考Andrew Ng老师给出的例子(详情可参考课程资料),如果给定基础特征的数量为100,那么在利用逻辑回归解决复杂分类问题时会遇到特征项会爆炸增长,造成过拟合以及运算量过大问题。
例如,
在n=100的情况下构建二次项特征变量,最终有5050个二次项。
随着特征个数 n 的增加,二次项的个数大约以 n^2 的量级增长,其中 n 是原始项的个数,二次项的个数大约是 (n^2)/2 个。
这是非常糟糕的情况,并且无法在一开始就进行优化,因为很难确定哪一个高次项是真正有用的,所以必须找到所有的二次项进行训练,在训练之后才能通过不同的权重判断哪一项是有用的。
而对于神经网络,可以通过隐层数量和隐藏单元数量来控制假设函数的复杂程度,并且在计算时只计算一次项特征变量。其实本质上来说,神经网络是通过这样一个网络结构隐含地找到了所需要的高次特征项,从而化简了繁重的计算。
参考资料
UFLDL Tutorial
http://ufldl.stanford.edu/tutorial/
Coursera - Machine learning( Andrew Ng)
https://www.coursera.org/learn/machine-learning
Coursera -ML:Neural Networks: Representation
https://share.coursera.org/wiki/index.php/ML:Neural_Networks:_Representation
Coursera -ML:Neural Networks: Learning
https://share.coursera.org/wiki/index.php/ML:Neural_Networks:_Learning
结语
下一篇文章会撰写关于神经网络模型训练方面的心得笔记,谢谢!
本文的文字、公式和图形都是笔者根据所学所看的资料经过思考后认真整理和撰写编制的,如有朋友转载,希望可以注明出处:
[机器学习] Coursera ML笔记 - 神经网络(Representation)
http://blog.csdn.net/walilk/article/details/50278697














 2824
2824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









