Google recently open-sourced its Artificial Intelligence/Numerical Computing library called TensorFlow. TensorFlow was developed by members of the Google Brain team, and has the flexibility to run on a variety of platforms – including GPUs and mobile devices.

TensorFlow’s methodology uses what they called data-flow graphs. Consider the following diagram from the Wikipedia page on Genetic Programming (which could have some interesting applications with TensorFlow, I think):
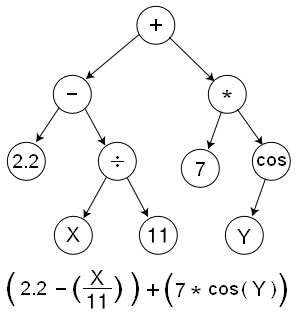 As you probably understood, the graphical structure is a way of representing a computational expression in the form of a Tree. Every node is an operation (TensorFlow calls them ops, short for operations). The non-leaf nodes are pretty easy to understand. Some leaf nodes are a special case of an operation, always ‘returning’ a constant value (like 7 or 2.2 in the Tree). Others (like X or Y) act as placeholders that will be fed in at the time of execution. If you look at the arrows, you will realize that their directions denote the dependencies between outputs of different nodes. Hence, data (TensorFlow calls them Tensors) will flow in the opposite direction along each node – Hence the name TensorFlow. TensorFlow provides other components over this graphical abstraction, like persistent memory elements that retain data (called Variables), and optimization techniques to fine-tune the parameters in these Variables in applications like Neural Networks.
As you probably understood, the graphical structure is a way of representing a computational expression in the form of a Tree. Every node is an operation (TensorFlow calls them ops, short for operations). The non-leaf nodes are pretty easy to understand. Some leaf nodes are a special case of an operation, always ‘returning’ a constant value (like 7 or 2.2 in the Tree). Others (like X or Y) act as placeholders that will be fed in at the time of execution. If you look at the arrows, you will realize that their directions denote the dependencies between outputs of different nodes. Hence, data (TensorFlow calls them Tensors) will flow in the opposite direction along each node – Hence the name TensorFlow. TensorFlow provides other components over this graphical abstraction, like persistent memory elements that retain data (called Variables), and optimization techniques to fine-tune the parameters in these Variables in applications like Neural Networks.
TensorFlow has a powerful Python API. The TensorFlow team has done an awesome job of writing the documentation (which is a little tricky to navigate). If you are completely new to this, heres a few links to get you started (in the order you should visit them):
1. Basic setup
2. Read this example to get a vague idea of what a TensorFlow code looks like.
3. Now read this explanation of the basic components of TensorFlow. It helps if you read the above example again, or simultaneously.
4. Read this detailed example of using TensorFlow for a common ML problem.
5. Once you have a decent understanding of the basic components and how they work, you can look at the Python docs for reference.
Now here is the code I wrote for K-Means clustering using TensorFlow. As a disclaimer, I will mention that this code is based on my (at the time of writing this) 2-day old understanding of how the library works. If you find any errors or know any optimizations possible, do drop a comment! The code is heavily documented, so do go through in-line docs.
import tensorflow as tf
from random import choice, shuffle
from numpy import array
def TFKMeansCluster(vectors, noofclusters):
"""
K-Means Clustering using TensorFlow.
'vectors' should be a n*k 2-D NumPy array, where n is the number
of vectors of dimensionality k.
'noofclusters' should be an integer.
"""
noofclusters = int(noofclusters)
assert noofclusters < len(vectors)
#Find out the dimensionality
dim = len(vectors[0])
#Will help select random centroids from among the available vectors
vector_indices = list(range(len(vectors)))
shuffle(vector_indices)
#GRAPH OF COMPUTATION
#We initialize a new graph and set it as the default during each run
#of this algorithm. This ensures that as this function is called
#multiple times, the default graph doesn't keep getting crowded with
#unused ops and Variables from previous function calls.
graph = tf.Graph()
with graph.as_default():
#SESSION OF COMPUTATION
sess = tf.Session()
##CONSTRUCTING THE ELEMENTS OF COMPUTATION
##First lets ensure we have a Variable vector for each centroid,
##initialized to one of the vectors from the available data points
centroids = [tf.Variable((vectors[vector_indices[i]]))
for i in range(noofclusters)]
##These nodes will assign the centroid Variables the appropriate
##values
centroid_value = tf.placeholder("float64", [dim])
cent_assigns = []
for centroid in centroids:
cent_assigns.append(tf.assign(centroid, centroid_value))
##Variables for cluster assignments of individual vectors(initialized
##to 0 at first)
assignments = [tf.Variable(0) for i in range(len(vectors))]
##These nodes will assign an assignment Variable the appropriate
##value
assignment_value = tf.placeholder("int32")
cluster_assigns = []
for assignment in assignments:
cluster_assigns.append(tf.assign(assignment,
assignment_value))
##Now lets construct the node that will compute the mean
#The placeholder for the input
mean_input = tf.placeholder("float", [None, dim])
#The Node/op takes the input and computes a mean along the 0th
#dimension, i.e. the list of input vectors
mean_op = tf.reduce_mean(mean_input, 0)
##Node for computing Euclidean distances
#Placeholders for input
v1 = tf.placeholder("float", [dim])
v2 = tf.placeholder("float", [dim])
euclid_dist = tf.sqrt(tf.reduce_sum(tf.pow(tf.sub(
v1, v2), 2)))
##This node will figure out which cluster to assign a vector to,
##based on Euclidean distances of the vector from the centroids.
#Placeholder for input
centroid_distances = tf.placeholder("float", [noofclusters])
cluster_assignment = tf.argmin(centroid_distances, 0)
##INITIALIZING STATE VARIABLES
##This will help initialization of all Variables defined with respect
##to the graph. The Variable-initializer should be defined after
##all the Variables have been constructed, so that each of them
##will be included in the initialization.
init_op = tf.initialize_all_variables()
#Initialize all variables
sess.run(init_op)
##CLUSTERING ITERATIONS
#Now perform the Expectation-Maximization steps of K-Means clustering
#iterations. To keep things simple, we will only do a set number of
#iterations, instead of using a Stopping Criterion.
noofiterations = 100
for iteration_n in range(noofiterations):
##EXPECTATION STEP
##Based on the centroid locations till last iteration, compute
##the _expected_ centroid assignments.
#Iterate over each vector
for vector_n in range(len(vectors)):
vect = vectors[vector_n]
#Compute Euclidean distance between this vector and each
#centroid. Remember that this list cannot be named
#'centroid_distances', since that is the input to the
#cluster assignment node.
distances = [sess.run(euclid_dist, feed_dict={
v1: vect, v2: sess.run(centroid)})
for centroid in centroids]
#Now use the cluster assignment node, with the distances
#as the input
assignment = sess.run(cluster_assignment, feed_dict = {
centroid_distances: distances})
#Now assign the value to the appropriate state variable
sess.run(cluster_assigns[vector_n], feed_dict={
assignment_value: assignment})
##MAXIMIZATION STEP
#Based on the expected state computed from the Expectation Step,
#compute the locations of the centroids so as to maximize the
#overall objective of minimizing within-cluster Sum-of-Squares
for cluster_n in range(noofclusters):
#Collect all the vectors assigned to this cluster
assigned_vects = [vectors[i] for i in range(len(vectors))
if sess.run(assignments[i]) == cluster_n]
#Compute new centroid location
new_location = sess.run(mean_op, feed_dict={
mean_input: array(assigned_vects)})
#Assign value to appropriate variable
sess.run(cent_assigns[cluster_n], feed_dict={
centroid_value: new_location})
#Return centroids and assignments
centroids = sess.run(centroids)
assignments = sess.run(assignments)
return centroids, assignments
Never, ever, EVER, do something like this:
for i in range(100):
x = sess.run(tf.assign(variable1, placeholder))
This may seem pretty harmless at first glance, but every time you initialize an op, (like tf.assign or even tf.zeros, you are adding new ops instances to the default graph. Instead, as shown in the code, define a particular op for each task (however specialized) just once in the code. Then, during every of your iterations, call sess.run over the required nodes. To check if you are crowding your graph with unnecessary ops, just print out the value of len(graph.get_operations()) during every iteration and see if its is increasing. In fact, sess.run should be the only way you interact with the graph during every iteration.
As visible on lines 138 and 139, you can call sess.run over a list of ops/Variables to return a list of the outputs in the same order.
There are a lot of intricacies of TensorFlow that this code does not go into, such as assigning devices to nodes, Graph collections, dependencies, etc. Thats partially because I am still understanding these aspects one by one. But at first glance, TensorFlow seems to be a pretty powerful and flexible way of doing AI/ML-based computations. I would personally like to explore its applications in developing dependency-based statistical metrics for data – for which I am currently using custom tree-like data structures. Lets hope this gesture by Google does lead to an increase in the applications and research in AI. Cheers!

Hey, I think your site might be having browser compatibility
issues. Whhen I look at your blog iin Safari, it looks fine but when opening in Internet Explorer, iit has
some overlapping. I just wanted to give you a quick heads
up! Othwr then that, terrific blog!
Thanks! And thanks for the pointing out. Will look into it 🙂
So quick and awesome article after releasing tensorflow
Thanks!
Hey Sachin, I’ve made some changes to your code to make it run faster (although it uses more memory).
You can see how I did it here: https://gist.github.com/narphorium/d06b7ed234287e319f18
I like the changes you made! Especially better use of the available Tensor containers. I am still getting used to the whole dimensions and slicing and concat stuff (always hated it in NumPy too).
Very nice job. Thanks a lot.
I want to remind the author, there is some problem when I use the project. The input parameters ‘vectors’ should have a data type of float64.
But as a user, I naturally put the vectors as integers. Users don’t know it need a input of float.
Hope you can add some remind in the function.
Thank you for your job again!
In the course of research for a paper about the application of TensorFlow to Genetic Programming, I came across this post. You may be pleased to learn that there is now a Python-based Genetic Programmig application suite which incorporates TensorFlow:
http://kstaats.github.io/karoo_gp/
We are very pleased with the results. The performance with TF is truly outstanding.
This is really very good. I thank you for sharing. This is supposed to be an easier case, but when you are exploring something new it is very helpful to have a map.
In the Euclidean distance calculation, the “tf.sub” must be deprecated so I substituted “euclid_dist = tf.sqrt( tf.reduce_sum (tf.squared_difference (v1, v2)))”. Also, the “tf.initialize_all_variables()” has changed to “tf.global_variables_initializer()”.
When calculating new centroid location I am getting an error “ValueError: Cannot feed value of shape (0,) for Tensor ‘Placeholder_2:0’, which has shape ‘(?, 24)” at “new_location = sess.run(mean_op, feed_dict={mean_input: array(assigned_vects)})” at the very end of your script. Any ideas how to fix this?
There appears to be some mis-match between the dimensionality of two vectors you use. I haven’t used the Python-TF in a while now, so I am pretty rusty. Though did you try just printing out the two vectors (or all that appear in the offending expression), so you know whats missing? I used this crude hack a lot while writing this early code.
this is old code and needs to be updated