







前面我们在是实现K-means算法的时候,提到了它本身存在的缺陷:
1.可能收敛到局部最小值
2.在大规模数据集上收敛较慢
对于上一篇博文最后说的,当陷入局部最小值的时候,处理方法就是多运行几次K-means算法,然后选择畸变函数J较小的作为最佳聚类结果。这样的说法显然不能让我们接受,我们追求的应该是一次就能给出接近最优的聚类结果。
其实K-means的缺点的根本原因就是:对K个质心的初始选取比较敏感。质心选取得不好很有可能就会陷入局部最小值。
基于以上情况,有人提出了二分K-means算法来解决这种情况,也就是弱化初始质心的选取对最终聚类效果的影响。
二分K-means算法
在介绍二分K-means算法之前我们先说明一个定义:SSE(Sum of Squared Error),也就是误差平方和,它是用来度量聚类效果的一个指标。其实SSE也就是我们在K-means算法中所说的畸变函数:
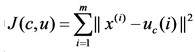
SSE计算的就是一个cluster中的每个点到质心的平方差,它可以度量聚类的好坏。显然SSE越小,说明聚类效果越好。
二分K-means算法的主要思想:
首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。
二分k均值算法的伪代码如下:
将所有数据点看成一个簇
当簇数目小于k时
对每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二后的总误差
选择使得误差最小的那个簇进行划分操作
Matlab 实现
function bikMeans
%%
clc
clear
close all
%%
biK = 4;
biDataSet = load('testSet.txt');
[row,col] = size(biDataSet);
% 存储质心矩阵
biCentSet = zeros(biK,col);
% 初始化设定cluster数量为1
numCluster = 1;
%第一列存储每个点被分配的质心,第二列存储点到质心的距离
biClusterAssume = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









